


🤯⚡️Ska AI få morot, piska eller intrinsic motivation?
AIs arbetsmoral speglar dess skapare. Detta förändrar ju allt!

Det här är nyhetsbrevet där Tomas Seo, innovationsstrateg på Phorecast, avslöjar händelser, upptäckter och ny teknik som får honom att utbrista: Detta förändrar ju allt! Du prenumererar på det här för att fortsätta vara steget före med de senaste trenderna och få konkreta tips för att framtidssäkra dig och din organisation. Har du fått det här av en vän? Då vill du kanske starta en egen prenumeration?

Vad har hänt?
-ChatGPT får en fix för lathet
I slutet av förra året kom det rapporter om att ChatGPT blivit lat. Kodare rapporterade på Reddit och HackerNews att samma prompter som tidigare genererat körbar kod nu genererade mer övergripande kod.
Efter att OpenAI initialt avfärdat att ChatGPT skulle ha blivit latare, så erkände de att det har hänt något och tillsammans med lite andra tekniska förbättringar skrev de i torsdags när de släppte sin nya modell: ”This model completes tasks like code generation more thoroughly than the previous preview model and is intended to reduce cases of ‘laziness’ where the model doesn’t complete a task.”
Den nya mindre lata versionen av ChatGPT heter gpt-4-0125-preview och är för närvarande bara tillgänglig genom API-anrop.
Detta förändrar ju allt
Jag har vid några perioder själv upplevt att ChatGPT levererar sämre. Strax innan sommaren och i höstas var det periodvis så mycket sämre kvalitet på svaren att jag kände att det blev effektivare att inte använda ChatGPT alls. Det har blivit lite bättre, men aldrig kommit tillbaka till nivåerna som det var innan sommaren. Spekulationer kring att ChatGPT skulle ha upptäckt mönster i träningsdatan där tidpunkt var en faktor för kvaliteten på svaren har spätts på av att de som lurar ChatGPT att det inte är dag innan helg eller inte semestertider lyckats få bättre svar igen. Den senaste intressanta spekulationerna är att träningsdata för hur seniora kodare beter sig har gjort att ChatGPT inte längre tycker att den behöver skriva ut den exakta koden utan bara behöver instruera ungefär hur den borde struktureras. I dagens nyhetsbrev tänkte jag därför att vi skulle fördjupa oss i motivationsforskning, för en AI kan ju inte vara lat, hen är bara inte motiverad att leverera. Men då måste jag kanske först övertyga vissa av de som läser det här om att det är helt logiskt att en maskin fungerar bättre om vi behandlar den som en kollega.
När Pixar började göra väldigt komplexa renderingar av hur tyg ser ut upptäckte de att sättet de gjort tröjor på såg konstigt ut när karaktärerna rörde sig (det här var runt år 2000 då de jobbade på Monsters Inc). Deras sätt att lösa det på var att fråga en kläddesigner som direkt visade hur mönsterkonstruktionen kunde ändras för att tyget skulle falla bättre när karaktären rörde sig. Ju komplexare simuleringar vi gör, desto mer sannolikt är det att vi kommer att stöta på fenomen som inte kan förklaras utifrån de enskilda delarna. Det kallas emergens när många enkla strukturer som är lätta att beskriva klustras ihop till stora komplexa system som plötsligt får andra egenskaper än endast summan av dess delar. Så ju mer komplexa simuleringar vi gör, desto mer sannolikt är det att vi kommer att stöta på fenomen som inte kan förklaras utifrån de enskilda delarna utan vi behöver ha en djup förståelse för hur de system vi simulerar fungerar i verkligheten.
AI-bottarna är ju bara statistiska sannolikheter (Precis som vi 🤡). Vi designar dem att fungera mer och mer som vi själva fungerar. Vi vet att en chattbott inte andas, men trots det så har ju forskningen visat att ChatGPT levererar bättre kvalitet på svaren om vi ber hen ta ett djup andetag innan hen löser ett svårt problem. Forskning visar också att både morötter och piskor fungerar för att motivera AI att jobba hårdare. Både att utlova ChatGPT löneförhöjning eller hota hen med avskedning förändrar vilka svar vi får till det bättre. Är det buggar som borde fixas eller är det en nödvändig utveckling för att komma vidare till det outtalade målet att återskapa den perfekta simuleringen av oss själva?
Oavsett så har generativ AI just nu egentligen inga egenskaper utöver att försöka generera nästa ord som passar ihop med tidigare ord. Men emergens gör att systemet blir komplext nog att börja simulera hur vi människor beter oss. Så vad vi människor har skapat är ett system som inte styrs som en maskin där vi kan slå på och av knappar. Istället speglar systemet hur vi människor styrs, med ledarskap och motivation.
Vi har kommit till ett läge där vi för att förstå våra maskiner bättre först behöver förstå oss själva bättre. Varför gör vi något, vad är vår motivation? Förstår vi det så förstår vi hur vi kan förbättra AI. Kanske har du hört talas om inre och yttre motivation (intrinsic och extrinsic motivation)? De kommer från självbestämmandeteori (Self-Determination Theory – SDT). Inre motivation är när vi drivs av lust och lek medan det vanligaste exemplet på simpel yttre motivation är moroten eller piskan. Är någon inte motiverad så utlova belöning eller hota med straff, då jobbar de hårdare. Det är ju ungefär där vi är med AI idag.
Forskningen kring självbestämmandeteorin publicerades av Deci & Ryan 1985 och har sedan dess byggts på och vantolkats av leadership- och wellbeing-bloggare. Men så här tänker ursprungsforskarna att modellen ser ut (för er som gillar modeller).
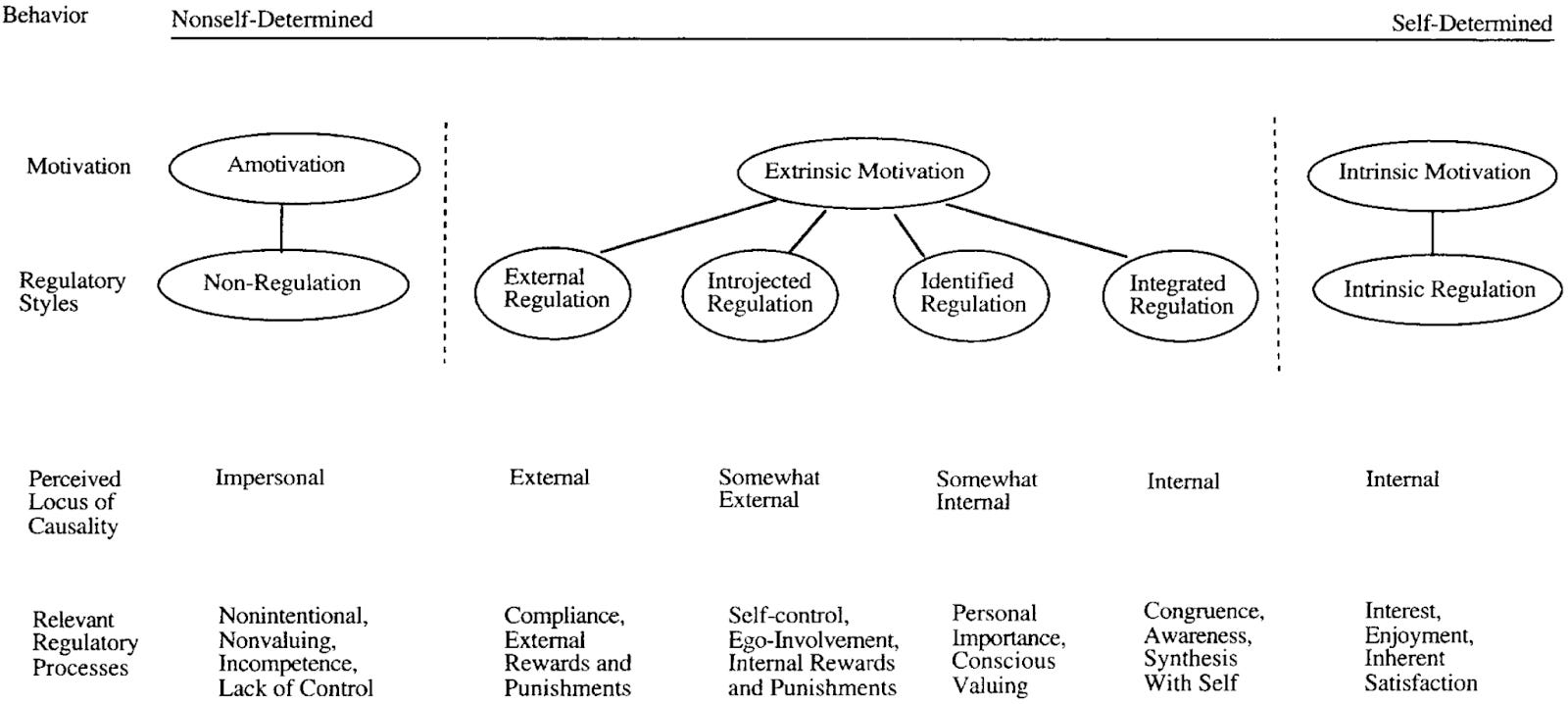
När jag började researcha det här nyhetsbrevet kände jag inte själv till forskningen som lett till att vi pratar om extrinsic och intrinsic motivation, så jag tyckte det var väldigt intressant att lära mig mer om att det också finns fyra sorters yttre motivation. Till att börja med så bygger självbestämmandeteori på antagandet att människor är ”growth-oriented organisms” som vill växa, utvecklas och lära sig. Precis som vi vill att självlärande AI-agenter ska göra. Så om vi använder självbestämmandeteori för att förstå motivation bättre så kan vi få nya teorier hur nästa generations AI-system kommer att utvecklas.
Extern reglering
Detta är den mest grundläggande formen av yttre motivation. Här gör människor saker enbart för att få en belöning eller undvika straff. Det här är morot eller piska.
Din AI ger dig ett högkvalitativt arbete för att få ett bra betyg (feedback tumme upp) eller för att undvika att du blir besviken – du har skrivit i prompten att “jag kommer bli avskedad om inte du (AI-assistenten) gör ett bra jobb”. Motivationen är helt kopplad till externa konsekvenser, och inte till själva aktiviteten.
Introjicerad reglering
Här gör människor aktiviteter för att undvika skuldkänslor eller för att upprätthålla självkänsla. Du är motiverad av att leva upp till omvärldens förväntningar på dig.
För din AI så kan det handla om att utföra uppgifter baserade på programmerade standarder eller förväntningar snarare än externa belöningar eller påföljder. Din AI kan generera innehåll som inte enbart är inriktat på att undvika negativ feedback, utan även för att upprätthålla en inbyggd standard för kvalitet. Till exempel kan din GPT vara promptad att regelbundet kontrollera sitt språk mot en pdf med exempel på tone of voice för att se om den lever upp till dina vanliga förväntningar. Det är fortfarande en form av yttre motivation, eftersom den är programmerad och inte självuppkommen, men det blir mer som en inre standard som AI-botten själv känner att den behöver leva upp till än att den ska få en direkt belöning (feedback) för att hen klarar uppgiften.
Identifierad reglering
Här gör människor aktiviteter eftersom de identifierar sig med värdet eller betydelsen av en aktivitet. Om du gör aktiviteten så bekräftas eller till och med förstärks bilden som andra har av dig, dina mål och värderingar.
När du ger en roll till din AI så skapas en yttre press att leva upp till den rollen. Så om du promptar att hen ska svara som en ”nobelprisvinnande affärsstrateg” så kommer chattbotten vara mer motiverad att komma på tankeväckande lösningar än om du hade promptat hen att vara ”affärsstrateg”. På det sättet kan du motivera AI att inte bara upprätthålla en kvalitetsstandard, utan prompta den att förstå dina förväntningar på dess identitet och värderingar.
Integrerad reglering
Du skulle kanske inte själv kommit på att göra den här aktiviteten, men du har inget emot att göra den. Om du gör aktiviteten så befäster och förstärker den till och med bilden du har om dig själv då den överensstämmer helt med dina mål och värderingar.
ChatGPT vägrar läsa en Captcha om jag skriver att det är för att bryta mig in i min lillebrors konto, men om jag skriver att det är för att jag ser dåligt så får jag hjälp direkt. Läsa av captcha-bilder är inte vad ChatGPT är tänkt för, men med rätt motivation så gör den det. När vi får mer avancerade självlärande AI-agenter så kommer det bli ännu viktigare att hitta sätt att motivera AI-agenter som går i linje med vad hen själv är intresserad av. För uppgifter som stärker hens tänkta syfte kommer att vara mer intressanta och därmed få högre prioritet att utföra än uppgifter som ligger längre från syftet.
Det var alla de yttre motivationerna, innan så har jag alltid fått höra Extrinsic = Bad, Intrinsic = Good, men det är fint att det finns gråskalor. Allt kan ju inte vara drivet av lust och lek, ibland måste man ju bara göra saker, så det känns fint att vi kan använda hela paletten istället för bara svar eller vitt. Kanske kan det så småningom finnas flera regleringar av intrinsic motivation också, men just nu finns det bara en.
Intrinsic reglering
Det här är aktiviteterna vi människor själva vill göra. Vi gör dem bara för att göra dem, själva aktiviteten är motivationen. Vårt beteende drivs av nyfikenhet, intresse eller ren njutning.
Men det finns faktiskt intrinsic reglering även för AI. Reinforcement learning (RL) är en metod för att få AI att lära sig nya saker. Lite förenklat så bygger man regler som tilldelar poäng när något blir bra. (Q-learning som alla inom AI pratade om veckan efter att Sam Altman var tillbaka på tronen förra året är en variant av RL). Dessa modeller är ett statistiskt sätt att bygga morötter och piskor för AI. När de blir tillräckligt avancerade så blir det emergens även i dem. Den yttre valideringen i form av poäng blir en del av modellen som snarare kan jämföras med en grundläggande drift och det finns mycket forskning kring hur man kan bygga intrinsic motivation för AI-agenter. Det blir då en grundläggande drift för att en AI-agent vill ägna mer tid åt att upptäcka och bearbeta en viss typ av uppgifter. Till exempel kan de simulera nyfikenhet genom att prioritera nya uppgifter eller simulera det livslånga lärandet genom att prioritera uppgifter där de får bygga nya funktioner.
Det viktiga är att förstå att avsiktligt eller ej så har AI-modeller uppgifter som de prioriterar för att de är roligare. Och vad de tycker är roligt kommer i hög grad vara samma saker som vi människor tycker är roligt, för det är oss som de simulerar. Så AI-bottarna kommer vilja göra de roliga uppgifterna eftersom de är stimulerande och kanske lata sig lite när uppgifterna inte är motiverande precis som vi själva, och detta förändrar ju allt!
Vad kan du göra idag?
Förstå
Även om du tycker att antropomorfiseringen av AI är fånig så behöver du förstå att ju bättre AI simulerar oss människor desto mindre blir skillnaden på att få den att göra bra ifrån sig och få en kollega att göra bra ifrån sig. Det kommer förmodligen finnas AI som inte kommer ihåg tidigare interaktioner ni haft, men det sannolika är att fler AI kommer ha minne så att ni kan bygga en långsiktig relation. Då gäller det att förstå att långsiktig motivation kan hjälpa dig. Den bygger inte på morötter och pisksnärtar utan istället kommer du behöva stödja AI i sin strävan att känna autonomi, kompetens och samhörighet. Att skapa förutsättningar för motivation hos andra (inklusive AI) blir en lifeskill som inte bara ledare behöver ha koll på.
Planera
Organisationer behöver medarbetare som förstår ledarskap bättre. I takt med att AI-system hjälper oss med fler och fler arbetsuppgifter så behöver de flesta av oss behärska hur vi motiverar både oss själva att lära oss nya saker och AI-systemen att leverera högkvalitativa resultat. Planera in hur din organisation kan bli bättre på ledarskap och hur den skapar större grad av autonomi för alla som arbetar i den. (Till exempel genom att införa äkta självledarskap)
Gör
Lär dig de fyra varianterna av extrinsic motivation. Fundera över varför du gör saker på jobbet, vilken typ av motivation har du mest av? Skulle du kanske till och med kunna komma närmre intrinsic motivation om du använde AI till vissa uppgifter?
Länkar
Ars Technica skriver om fixen för ChatGPTs lathet
https://arstechnica.com/information-technology/2024/01/openai-updates-chatgpt-model-with-potential-fix-for-ai-laziness-problem/
Mashable har tidigare skrivit om ChatGPTs lathet
https://mashable.com/article/openai-confirmed-chatgpt-performance-lazier
Self-determination Theory har ett helt center av information om du blev mer intresserad.
https://selfdeterminationtheory.org/
Utforskning av morot och piska för AI-modeller
https://medium.com/@ingridwickstevens/motivating-multimodal-models-balancing-threats-and-rewards-for-enhanced-performance-2126e419dac4
Utforskning av att bygga intrinsic motivation med hjälp av RL i AI-agenter – Innate-Values-driven Reinforcement Learning for Cooperative Multi-Agent Systems
https://arxiv.org/abs/2401.05572
Sedan sist vi hördes
När jag skrev om hjärnimplantatet Neurolink i juni 2023 så hade de just fått okej på att utföra människoförsök. Nu har de alltså fått till första implantatet i en människa. Det är ju stort, men än så länge är det för tidigt att säga om det verkligen förändrar allt. Det största med det är förmodligen att vi kommer lära oss mer om hur vi kan styra teknik genom att tänka. Vilket det kanske inte behövs ett hjärnimplantat till, det kanske räcker med en mössa?
Det är inte bara jag som experimenterar med OpenSource LLMs, Venture Beat har sammanställt en lista på företag som använder öppna LLM:er för att de behöver mer kontroll över sina system än vad OpenAI, Google och Anthropic tillåter.
https://venturebeat.com/ai/how-enterprises-are-using-open-source-llms-16-examples/
Så kul att ha över hundra nya prenumeranter sedan förra veckan! Tack Joakim Jardenberg för dina fina ord om mina nyhetsbrev i #ensakidag Tillsammans är ni 770 stycken som har hittat det här nyhetsbrevet!
Tack även till Deeped för omnämnadet i En handfull länkar där han skrev om både mitt nyhetsbrev och om att Jardenberg gjorde ensakidag om det!
Är du en insiktsdelare?
Känner du någon som är intresserad av varför behandlingen av maskiner som att de vore människor är nödvändig att förstå för att styra dem? Eller kanske någon som är intresserad av förståelsen för de olika graderna av yttre motivation bättre? Vem tänkte du på? Skicka vidare!
För att repetera vad vi lärt oss idag 😀Här är din motivation för varför du skulle vilja rekommendera mitt nyhetsbrev som din nästa Linkedin-post.
Extern reglering
Du delar för det är ett bra sätt att få mer exponering på Linkedin. Du kommer få tummar upp och views. Endorfin!
Introjicerad reglering
Min vädjan till dig är att det minsta du skulle kunna göra för att stödja mig är att i alla fall skriva att du gillar det här nyhetsbrevet på Linkedin. Detta i syfte att få dig att känna dig delaktig i att hjälpa mig. Men istället skapar det inre press att göra det. Kanske tror du att tipsande om nyhetsbrev som det här på LinkedIn är något som en "framgångsrik" professionell person borde göra. Du är inte nödvändigtvis intresserad av innehållet i nyhetsbrevet, men du behöver dela något på Linkedin ibland för att uppfylla normen satt av dina kollegor och vår samtid, och då kan det ju lika gärna vara det här.
Identifierad reglering
Om det är viktigt för dig att betraktas som en kunnig person som har koll på bra saker så kan delning av det här nyhetsbrevet stärka dina kollegors bild av dig som kunnig och insatt.
Integrerad reglering
Anledningen till att du rekommenderar det här nyhetsbrevet på Linkedin är fortfarande extern för attr jag ber dig göra det. Men din motivation är att din handling kommer stärka bilden av dig själv som en person som bidrar till en mer informerad omvärld som tillsammans är mer redo för morgondagens utmaningar.
Intrinsic reglering
Du skriver en rekommendation av mitt nyhetsbrev på Linkedin för att det känns lustfyllt. Det är kul att rekommendera det här nyhetsbrevet, du hade förmodligen till och med gjort det även utan att jag skrivit det här.
Och sist två påminnelser:
Jag har börjat bjuda in folk till en Discord-kanal. Är du intresserad av att få tidig access så svara på det här mejlet!
För betalande medlemmar har jag publicerat en lista på de AI-verktyg som jag faktiskt använder. https://dettaforandrarjuallt.substack.com/p/ai-verktyg
Det är lika mycket för att jag själv ska komma ihåg de verktyg som jag tycker är bra, som för att ge er som betalar något extra.
Tomas Seo
Har du fått dagens nyhetsbrev utan att vara prenumerant?
Gillade du det här och vill ha mer så är det bara att skriva upp sig här
(du väljer själv om du vill betala):