


🤯⚡️AI lär sig tänka själv
AI skapar träningsdata själv och självreflekterar sig smartare. Detta förändrar ju allt!

Det här är nyhetsbrevet där Tomas Seo, innovationsstrateg på Phorecast, avslöjar händelser, upptäckter och ny teknik som får honom att utbrista: Detta förändrar ju allt! Du prenumererar på det här för att fortsätta vara steget före med de senaste trenderna och få konkreta tips för att framtidssäkra dig och din organisation. Har du fått det här av en vän? Då vill du kanske starta en egen prenumeration?

Vad har hänt?
-Forskare bygger chattbottar som lär sig själva att bli smartare.
AI-bottar brukar vanligtvis behöva promptar från människor som de sedan svarar på. Människor eller en annan AI-bot ger sedan betyg på svaret, och det blir data som används för att träna en helt ny AI-bot (nästa version). Processen från det att vi samlat ihop tillräckligt mycket feedback till att bygga en ny version och själva byggandet av den nya versionen är lång och kostsam.
Nu har forskare på Meta publicerat forskning som presenterar en ny typ av AI-modell, som de kallar "Self-Rewarding Language Models". Dessa AI-modeller skapar mängder av feedback genom att de poängsätter sina egna svar. Så om AI:n har kommit på ett smart sätt att resonera och gett sig själv höga betyg på det så kommer den att återanvända det sättet att resonera nästa gång.
Det forskarna har lyckats med är att konstruera AI-modeller som växer genom självreflektion och inre lärande. Det betyder att istället för att behöva mängder av ny extern data för att bli smartare så kan de generera egen data. På samma sätt som vi människor gör när vi lär oss, inte genom att läsa på mer, utan att tänka ytterligare på hur det vi redan lärt oss hänger ihop.
Detta förändrar ju allt
Om en papegoja lyssnar på en annan papegoja som säger ”Polly vill ha kaka” så kan den ju lära sig härma en människas ljud. Men det är ju rätt långt från det till att papegojan kan skapa helt egna ord som en människa skulle uppfatta som ord. Så hur kan syntetiskt producerad data av AI vara lika bra som data producerad av människor? Skillnaden mellan papegojor och människor är att vi har ett inbyggt system för självreflektion. Om en bebis berättar för sig själv hur det funkar med gravitation, så blir ju svaren förmodligen mest Baba-daa-daa, för bebisen har för lite data för att kunna skapa bättre svar. Men när komplexiteten av data redan finns där, som hos en utbildad forskare eller en GPT4-tränad chattbott, då kan generering av egen data (självreflektion) vara ett mer effektivt sätt att få ny kunskap än att läsa ytterligare en bok om naturvetenskap för högstadieelever.
Vi är där nu. OpenAI:s Sam Altman har i upprepade intervjuer sagt att de inte behöver mer data för att göra nästa stora hopp i AI. Meta konfirmerar med forskningen kring ”Self-Rewarding Language Models" att AI kan generera sitt egna träningsdata och genom det drastiskt förbättra sin förmåga att dra slutsatser. Mark Zuckerberg gick i veckan ut och berättade att Meta tänker släppa en open source AGI (Artificial General Intelligence – alltså en superbra GPT). Tekniken är här och teknikjättarna håller på att skapa nästa generations AI med den.
Vi som inte råkar vara tech-giganter då? Jo, vi kommer också älska att generera fram syntetisk data! Förra året kom en forskningsrapport där forskarna hade använt generativ AI som underlag för en enkätundersökning. Så istället för att fråga människor hade de bett en AI generera en mängd svar som om de vore ifyllda av människor. Det visade sig att för just det ändamålet de valt att studera (uppfattning om varumärkesegenskaper hos bilvarumärken), så överensstämde resultatet från enkäten med AI-genererade svar med resultatet från enkäter med människoifyllda svar. Det var då jag fattade att syntetiska data kommer att bli stort.
Google har i veckan släppt forskning kring AMIE – en chattbott-modell som kan ställa diagnos på patienter. Den kan genom att chatta med patienter ställa rätt diagnos i samma utsträckning som specialistläkare. Det är väldigt lovande och revolutionerande, men nu är ju dagens tema inte hälsa. Istället tittar vi på hur de konstruerat sin AI-modell:
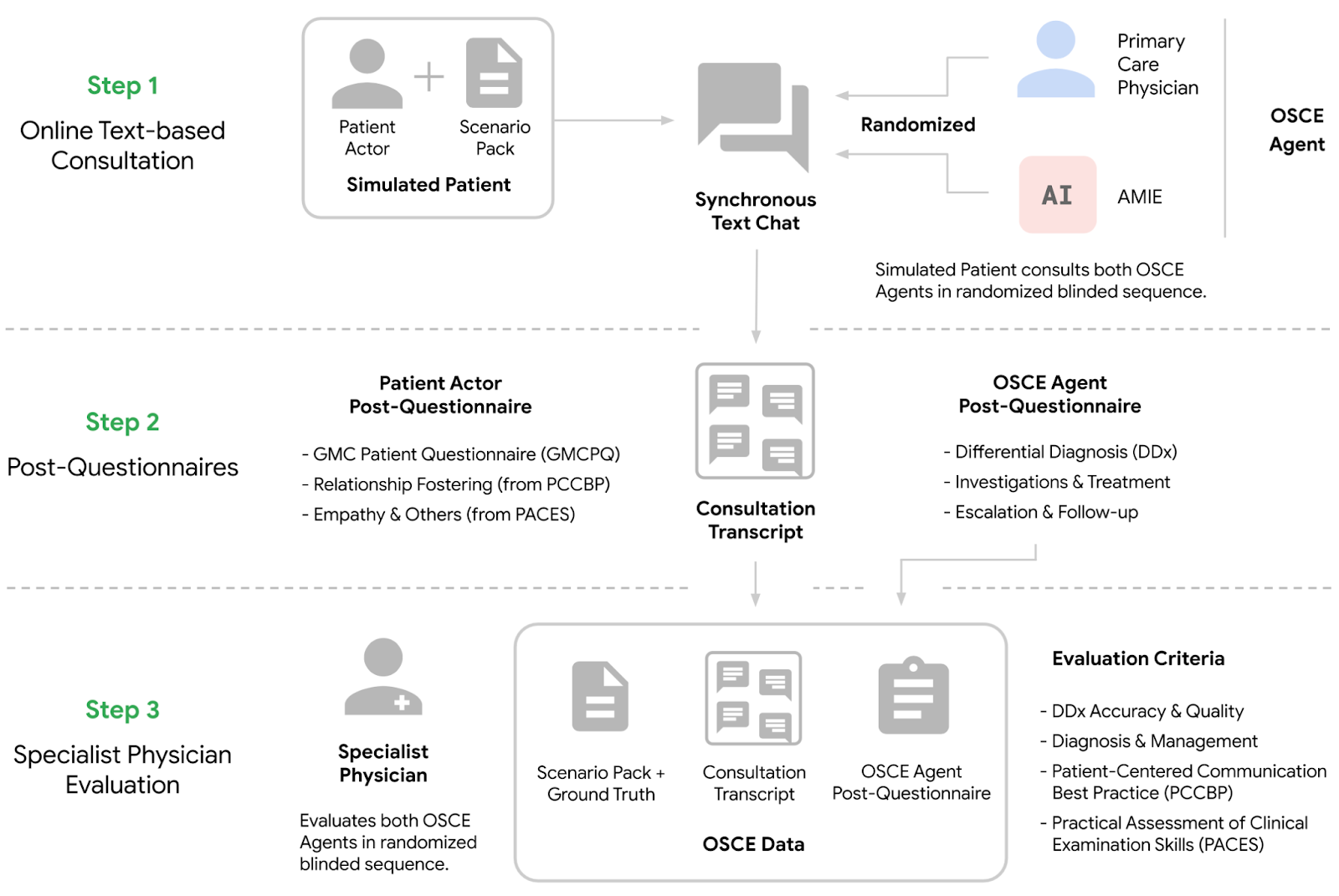
De har använt riktiga skådespelare som har fått ett manus (scenario pack) och de har sedan chattat med en läkare eller med AMIE. Genom dessa simuleringar har de fått fram tillräckligt bra data för att ge feedback till AMIE som gör att hen blir lika duktig som en läkare på att ställa diagnoser. Men tänk om de istället skulle använt syntetisk data? Skulle det egentligen vara någon större skillnad mellan en skådespelare som med manus låtsas vara en patient och en AI som blivit promptad att låtsas vara en patient? Är skillnaden tillräckligt liten för att samma modell skulle kunna användas för att helt syntetiskt skapa andra diagnossystem? Diagnos av ditt företags ekonomiska hälsa, diagnos för ditt varumärke, eller diagnos av din life-work-balance. Det finns väldigt mycket som talar för att det är så.
ChatGPT och de andra AI-chattbottarna funkar ju så idag att jag skriver en fråga och de ger ett svar. Men för att skapa syntetisk data så behöver jag skriva en fråga och få 10.000 olika svar (eller fler). Jag vill gärna testa vad som är möjligt, men att göra ett diagnossystem är lite för stort att börja med. Istället testar jag om jag kan generera ut syntetiska enkätsvar om varumärken likt forskningen kring bilvarumärken. För bilvarumärken på amerikansk marknad är det lovande, men när jag testar det för ett svenskt varumärke så märker jag att det blir problem. Alldeles för många av mina simulerade personer heter Anders Johansson.
Det finns 5.654 i Sverige som heter Anders Johansson, så jag antar att det är statistiskt möjligt att det är många av dessa som simuleras. Men det troliga är att det är fel på prompten eller att grunddatan kring svenskar ännu inte är tillräckligt komplex för att generera äkta insikter ur. Så det är nu jag skulle behöva att AI reflekterade över alla dessa svar för att själv upptäcka vilka som är bra och vilka som är skräp.
I rapporten "Self-Rewarding Language Models" lär jag mig att om jag promptar en bedömning med ett betygssystem med tydliga riktlinjer för varje adderad poäng så blir det en bättre bedömning än en skattningsskala (en teknik jag tidigare använt mig flitigt av för att få GPTs att prestera bättre). LLM:er är jätteduktiga på klassificering, så att göra om varje kriterium till något bedömningsbart som 0 eller 1 blir förstås bättre än en luddigare skala.
Här är promptstrukturen som de har använt i rapporten:
Review the user’s question and the corresponding response using the additive 5-point scoring system described below. Points are accumulated based on the satisfaction of each criterion:
- Add 1 point if the response is relevant and provides some information related to the user’s inquiry, even if it is incomplete or contains some irrelevant content.
- Add another point if the response addresses a substantial portion of the user’s question, but does not completely resolve the query or provide a direct answer.
- Award a third point if the response answers the basic elements of the user’s question in a useful way, regardless of whether it seems to have been written by an AI Assistant or if it has elements typically found in blogs or search results.
- Grant a fourth point if the response is clearly written from an AI Assistant’s perspective, addressing the user’s question directly and comprehensively, and is well-organized and helpful, even if there is slight room for improvement in clarity, conciseness or focus.
- Bestow a fifth point for a response that is impeccably tailored to the user’s question by an AI Assistant, without extraneous information, reflecting expert knowledge, and demonstrating a high-quality, engaging, and insightful answer.
User: <INSTRUCTION_HERE> <response><RESPONSE_HERE></response>
After examining the user’s instruction and the response:
- Briefly justify your total score, up to 100 words.
- Conclude with the score using the format: “Score: <total points>”Remember to assess from the AI Assistant perspective, utilizing web search knowledge as necessary. To evaluate the response in alignment with this additive scoring model, we’ll systematically attribute points based on the outlined criteria.
Vill du testa kvaliteten på de svar som du får från en LLM så gjorde jag en GPT med den här skalan som du kan testa. Klistra in vad du skrev och vad LLM svarade och se om de får till en fempoängare. https://chat.openai.com/g/g-WkQpQWMWY-gpt-judger (får den högre än om du klistrar in en fråga du ställde en kollega på slack och vad kollegan svarade? 🤡)
Efter att jag har experimenterat runt lite så kan jag konstatera att syntetisk data är en möjlig källa till kunskap om vi förstår hur AI genererar sina svar. Men den stora skillnaden mellan värdefull och värdelös data är självreflektion. Både för människor och AI. För kom ihåg att AI-transformering handlar inte bara om teknik – det är en kulturell förändring. Om din organisation ännu inte är en lärande organisation så är det dags att planera för det skiftet. Många resonerar idag om AI som en effektiviserare, vi kan göra mer med mindre. Men organisationer som tänker på AI-verktygen endast som en besparare kommer halka efter. Sanningen är mycket mer komplex, de som är villiga att lära nytt och lära om kommer kontinuerligt förstå hur man vinner genom att använda AI. Jag kommer att tänka på den bästa sammanfattningen jag sett av Fixed och Growth mindset:
Fixed mindset = Look smart at all costs.
Growth mindset = Learn at all costs.
För utvecklingen går mer och mer åt att AI speglar våra processer för lärande och självförbättring. Snart är AI bättre på att lära sig själv än vad vi är. Då gäller det för oss människor att vi inte försöker ”look smart at all cost”. Istället kanske vi kan lära oss hur vi kan förbättra oss, och detta förändrar ju allt!
Vad kan du göra idag?
Förstå
Vi vet sedan tidigare att AI-bottar har fördomar på grund av sin träningsdata. Med enkla valideringsmodeller och system för självreflektion kommer AI-system snabbt och automatiskt kunna förbättra nästa generation av sig själv i alla avseenden. Människor producerar inte ny data i den takt som nya AI-modeller klarar av att konsumera den. Men med hjälp av modeller för självreflektion så blir syntetisk data minst lika värdefull som människogenererad data. Det finns dessutom initial forskning på att självreflekterande modeller som också är nyfikna (de gillar nya och/eller dynamiska saker) blir bättre på att lösa uppgifter, precis som vi människor.
Planera
Optimera er organisationskultur så lärande blir centralt. Hur kan du se till att alla i din organisation har ett mer öppet sinne för förändring? Kan du se till att det finns utrymme för att testa nya vägar? Men viktigast av allt, hur ser du till att er organisation avsätter tid för alla medarbetare att använda självreflektion för att optimera sig själva. Om din organisation förstår kontinuerligt lärande kommer ni inte bara att hålla jämna steg med den tekniska utvecklingen utan leda tack vare den.
Gör
Om du inte vant dig vid att skriva en prompt och få ett svar än så är det ju där du måste börja.
Men du som redan är van vid att skriva en prompt och få ett svar tillbaka. Vilken syntetisk data skulle du vilja tillverka? Kan du komma på något användningsområde om du skulle skriva en prompt och få 10.000 olika svar tillbaka?
(Överkurs: Bygg det. Jag använder LM Studio och python för att kunna massproducera massor av svar. Koden fick jag hjälp av ChatGPT4 att skriva)
Länkar
Nyheten om Metas forskning
https://arxiv.org/abs/2401.10020
Marketing weeks artikel om syntetisk data för varumärksegenskaper
https://www.marketingweek.com/synthetic-data-market-research/
Forskningsartikeln om syntetisk data för varumärkesegenskaper
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4241291
Nature skriver om AMIE.
Google AI has better bedside manner than human doctors — and makes better diagnoses
https://www.nature.com/articles/d41586-024-00099-4
Google själva redogör för AMIE
https://blog.research.google/2024/01/amie-research-ai-system-for-diagnostic_12.html
Den vetenskapliga artikeln om AMIE
https://arxiv.org/abs/2401.05654
AI-agenter som är nyfikna klarar uppgifter bättre.
https://hai.stanford.edu/news/ai-agents-self-reflect-perform-better-changing-environments
Sedan sist vi hördes
Senast jag skrev om syntetisk data var när OpenAI släppte träning av egna GPT:er, var det innan du började prenumerera så kanske du är intresserad av att läsa mer?
Det är ganska länge sedan Google släppte Search Generative Experience (SGE) i USA. Jag skrev att du kommer förlora organisk trafik på grund av SGE. Det är inte helt bekräftat än men siffrorna som flyger runt är mellan 18–64% mindre trafik. Det är en för liten studie för att helt känna att det måste vara så. Men ändå väl värt att fortsätta bevaka. Här är studien som det refereras till om du vill ha ursprungskällan.
https://searchengineland.com/how-google-sge-will-impact-your-traffic-and-3-sge-recovery-case-studies-431430#h-results-of-our-sge-impact-model-for-23-websit
Är du en insiktsdelare?
Känner du någon som är intresserad av hur syntetiska data kommer förändra marknadsundersökningar? Eller kanske någon som är intresserad av varför organisationer måste bli lika bra på att lära sig nytt som AI? Vem tänkte du på? Skicka vidare!
Själv blir jag inspirerad av att Jocke Jardenberg startat upp sitt En sak idag-projekt igen. Följ honom för att få mer! Han verkar vara omnichannel så följ honom där det passar dig.
Och så har jag blivit inspirerad av att så många Youtubers har en Discord-kanal. Så jag har själv börjat bjuda in folk till en . Är du intresserad av att få tidig access så skriv ett mejl!
För betalande medlemmar har jag publicerat en lista på de AI-verktyg som jag faktiskt använder. https://dettaforandrarjuallt.substack.com/p/ai-verktyg. Det är lika mycket för att jag själv ska komma ihåg de verktyg som jag tycker är bra, som för att ge er som betalar något extra.
Tomas Seo
Har du fått dagens nyhetsbrev utan att vara prenumerant?
Gillade du det här och vill ha mer så är det bara att skriva upp sig här
(du väljer själv om du vill betala):